Kumar, who is lead on the AKD project, asked me a simple question a few months back: what does it cost to run our AI agent in production for the AKD team? How would we convey or calculate this to other teams who would want to use AKD?
I didn't really know how to answer it — I didn't even know what all is involved. I have been helping manage backend, frontend, and infrastructure for running agentic workflows, but I hadn't been involved in actual agent development myself.
I thought this could be a good opportunity to learn what is involved, and that it would also help me learn more about agents and LLMs themselves. Kill multiple birds with one stone.
I didn't know much about token rates, cache hit rates, tool overhead, or traffic profiles, or which ones mattered most. So I took the longer route — 15 nights of evenings and weekends instead of a 2-day spreadsheet — to get the complete map before I trusted any number.
The first POC
I built an AI-enabled calculator POC. There were components for calculating cost, and I was trying to get AI to parse the user's intent and auto-select which components to activate. It was kind of working.
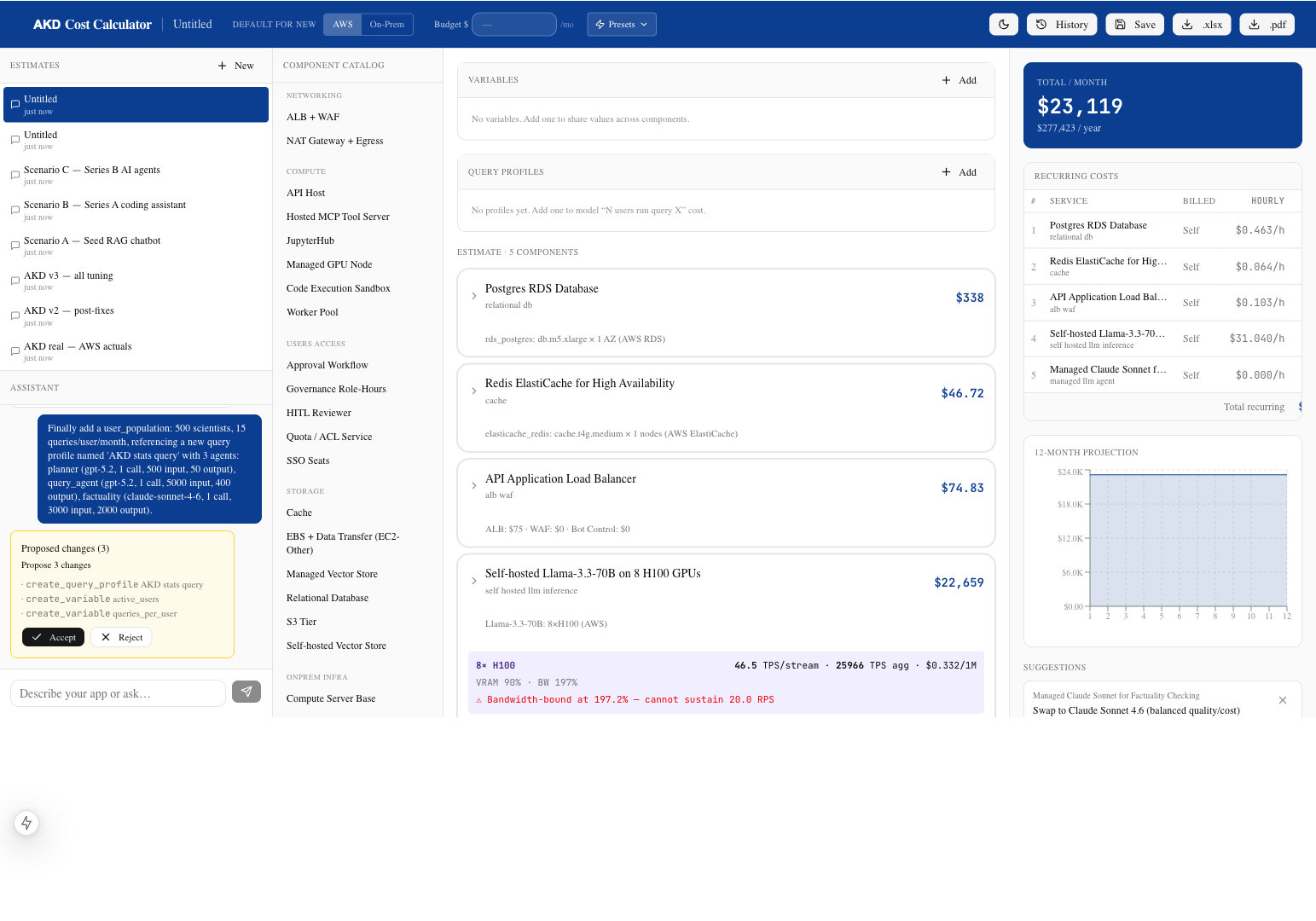
But after I had this prototype, there was an urgent need to present some numbers to stakeholders. Along with Kumar, Buddy, who is our deputy manager for DSE, had also asked several times for a cost estimate, because EIE was planning to have a public chat interface and the costing mattered a lot.
Paridhi, who is leading backend efforts for EIE and AKD, ran the real experiments — built a spreadsheet, did some back-of-envelope math, made a few best-guess assumptions. She got a number we could defend if anyone asked. She worked with Gjore, Lily, and other members of the EIE team to present them to stakeholders.
In the meantime I tried to build simulated numbers to match her math. I pivoted from the chat-driven idea and built a single-page calculator just for EIE.
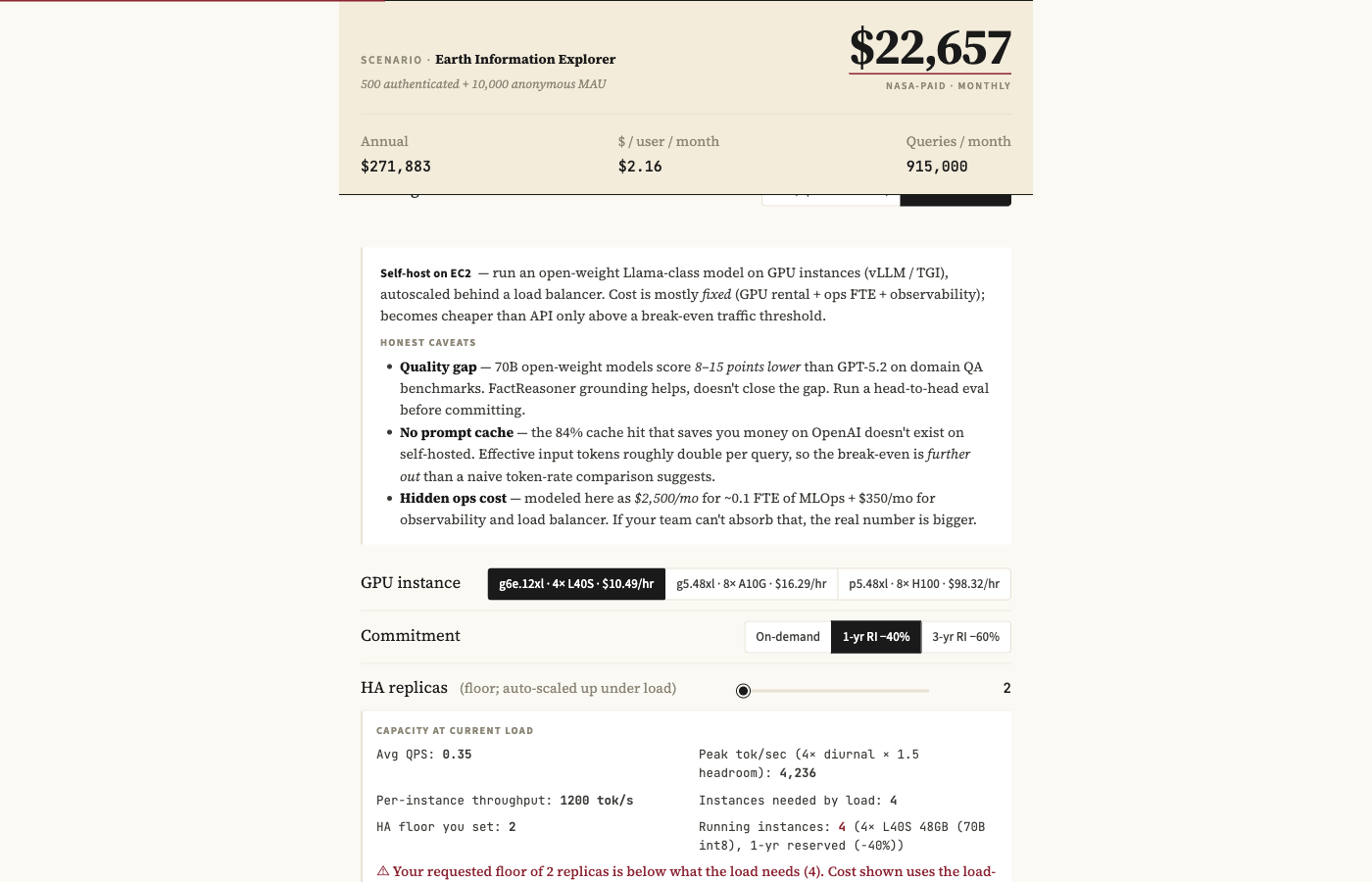
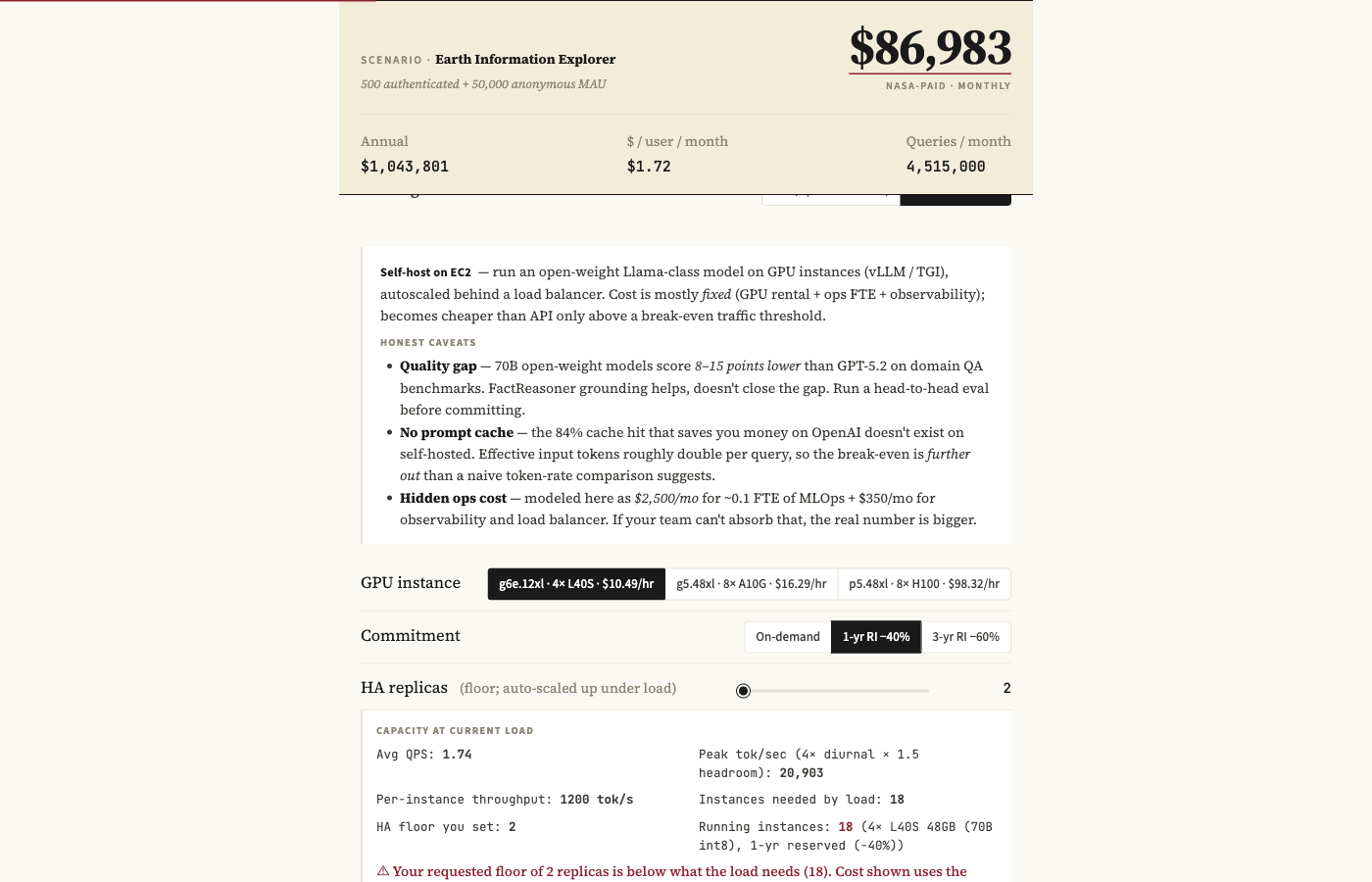
It was a single-page interactive cost estimator for a NASA-style public-facing LLM agent. User adjusts ~20 controls (traffic, model, caching, rate-limiting, FactReasoner, hosting) and a sticky headline block recomputes monthly cost in real time, with full breakdowns and an API-vs-self-host comparison.
The full feature list ~20 inputs across traffic, model choice, caching and rate-limiting; full cost breakdowns; an API-vs-self-host comparison; break-even search; a sensitivity tornado chart; and an embedded, runnable Python reference implementation that verifies against the page.
- Two-segment population — authenticated NASA scientists + public visitors, each with MAU / sessions-per-day / queries-per-session
- Bot multiplier (1.0–3.0×, clamped by rate-limit strategy)
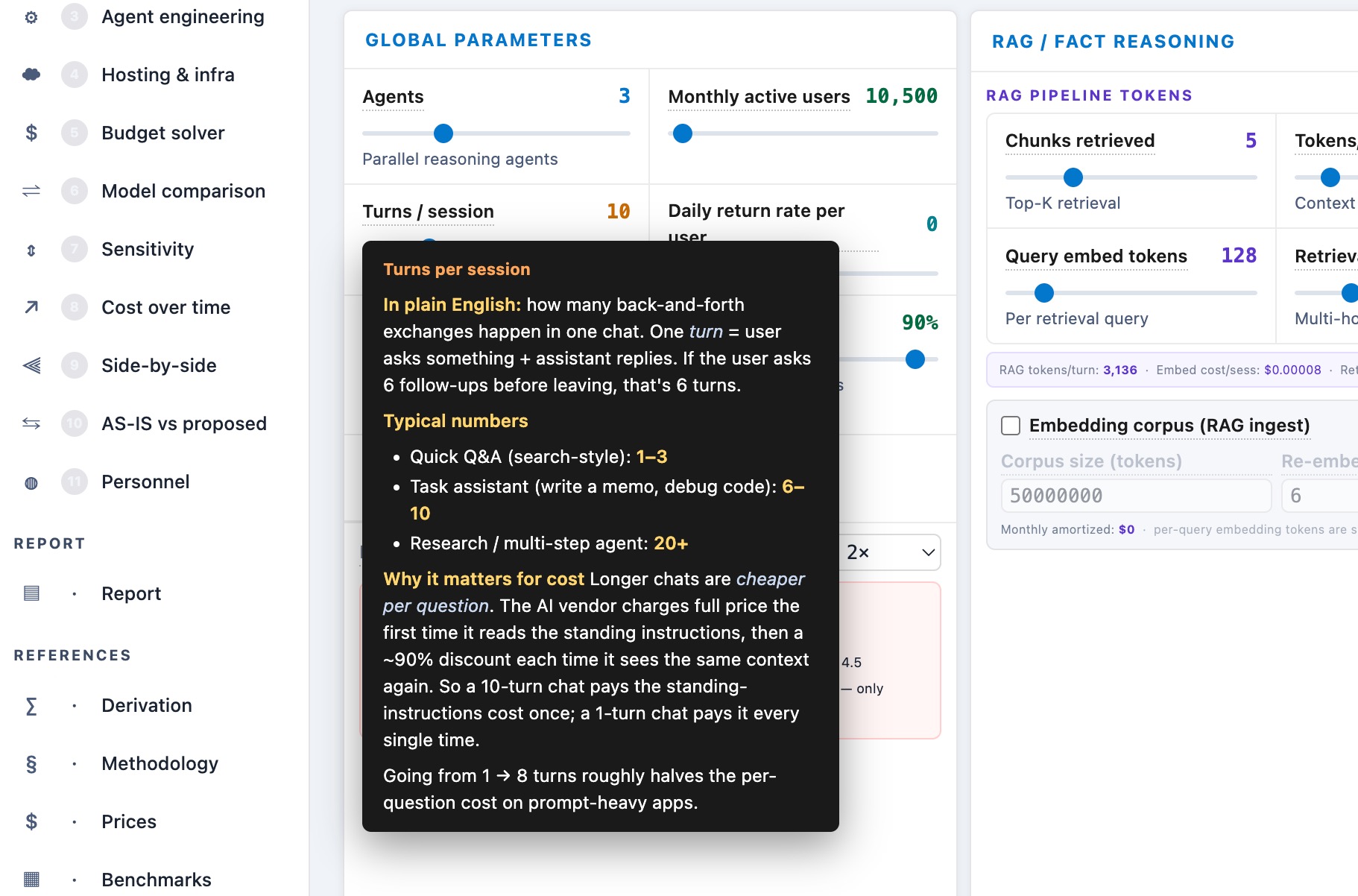
- Prompt-cache hit rate — slider with session-length adjustment (±1% per turn off a 6-turn baseline)
- Traffic mix presets — Worst-case / Mixed / Lookup-heavy across five query shapes
- Rate-limit strategy — None / Edge-WAF / Session+IP / Full WAF+Bot Control+CAPTCHA, each with cost + bot ceiling
- Data-source egress mode — same-region / Requester-Pays Earthdata / cross-region
- 11 model options — GPT-5.5/5.4/5.2/5.1/5/mini/nano, GPT-4o/mini, Claude Opus 4.7, Gemini 3.1 Pro
- Billing tier — Standard / Flex / Batch / Priority
- FactReasoner — coverage slider + variant (FR1/FR2/FR3) + atomizer model + NLI host (API / EC2 g5 / EC2 g6) + retrieval source (Wikipedia / Serper)
- Daily LLM spend cap — hard ceiling that refuses queries past threshold
- BYOK share, static edge-cache %
- Launch-week burst — 7 days at 1.0–5.0× sustained
- Compute platform — Fargate / EKS / self-managed K8s
- Region — us-east-1 / GovCloud (+25%)
- Multi-AZ on/off
- Self-host config — GPU instance (g6e.12xl / g5.48xl / p5.48xl), commitment (on-demand / 1-yr RI / 3-yr RI), HA replicas, tokens/query, optimistic vs realistic cost mode
- Sticky headline — monthly, annual, $/user/month, queries/month
- Approval-ready decision banner with guardrails summary
- "Recommended baseline" one-click pre-fill
- Multi-section cost breakdown — LLM API capped/uncapped, FactReasoner variable + fixed, infra lines, self-host stack
- API-vs-self-host comparison table with fair-comparison dual rows (capped + uncapped API vs self-host)
- Break-even query volume — binary-search, instance-step-aware
- Animated sensitivity tornado chart — ±30% bars for top cost drivers
- Traffic projection bar stack
- Risk/warning callouts — unrealistic scale, underprovisioned replicas, daily-cap refusals, bot-factor clamping
- Scroll-progress hairline, collapsible details sections, glossary, dated sources
- Per-query cost blending across five query shapes with per-shape token factors
- Segment-aware cache rates (authenticated vs public, blended)
- Session-length cache adjustment; refusals get zero cache
- Daily LLM spend cap with refusal counting
- BYOK shift (authenticated only)
- FactReasoner variant math — FR1 = 24 NLI calls / FR2 = 160 / FR3 = 350
- Self-hosted NLI toggle (variable cost → 0, fixed pod cost appears)
- Self-host capacity sizing — avg QPS × tokens/q × 4× diurnal × 1.5× headroom; ceil to instances; HA floor = 2; effective TPS = benchmark × derate (100% optimistic / 75% realistic)
- GovCloud +25% uplift on infra (not FTE); multi-AZ doubles RDS
- Launch-week burst split (7 burst + 23 steady)
- Hidden K8s FTE line ($5,333/mo) only when self-managed K8s + realistic mode
- Embedded Python reference implementation — ~1,600-line
<script type="text/x-python">block in the HTML; extractable and runnable aspython eie-cost-calculator.py --test(verifies against HTML) or--json. Zero pip dependencies. - Fair-comparison dual rows when daily cap is active
- Modeled worst-case computed alongside expected cost (7 days × 10× sustained) for approval conversations
- Query-shape token factors measured relative to "Query A" (84,490 in, 854 out)
- Vanilla HTML/CSS/JS, no framework, one external dep (Google Fonts)
- State held in DOM, serialized to
#c=base64urlhash on every change so state roundtrips cleanly - All cost math is pure-function composition over DOM reads
- Embedded Python mirrors the JS math to three decimal places
Paridhi's spreadsheet already had the EIE team covered. What I was building was more complicated than they needed, and harder to verify or communicate end-to-end. The team rightly used Paridhi's numbers to talk to stakeholders.
I kept going on personal time because the question itself stayed with me — and I wanted a tool that would help the next team to ask, not just EIE: something reusable they could pick up, not a one-off spreadsheet that lives in someone's inbox. So I built a generalized version, one that could serve AKD and any other NASA team facing the same procurement question.
Building such a calculator had been on my mind even before the EIE use case — Kumar had asked for it many times to present to Rahul, Senior Data Science Strategist at NASA, leading AI R&D and Foundation Models for Science, and the lead on the AI for Science Project at MSFC ODSI, which includes the AKD sub-project.
Although I wanted a chat-based calculator — where the team would describe their use case, AI would construct the architecture, choose components matching the query, and build out the cost, all in natural language — it was slow going. My time was split across several projects — Research Repository, Science Analytics Platform, AKD, Data Systems Evolution — and home was already full.
I resorted to vibe coding to build this — but boy, it takes a lot of time and energy to work with AI. You have to verify its output and its math, and build multiple verification gates and cross-checks before you can trust what it produces.
The token simulator (turned out richer than expected)
The first thing I built was a token simulator — a browser-based engine that mocks LLM calls with adjustable knobs, so teams could predict cost without hitting real APIs.
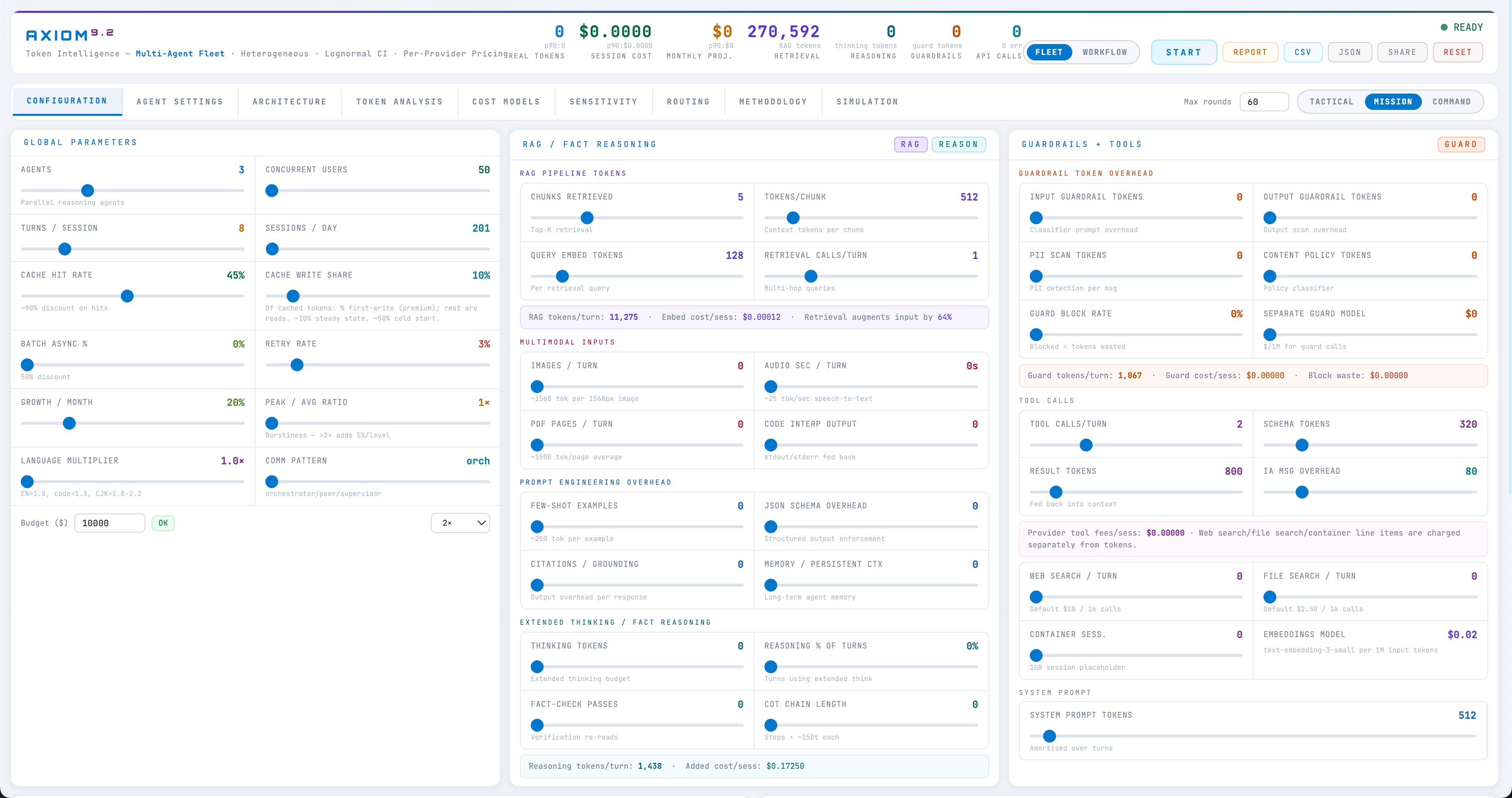
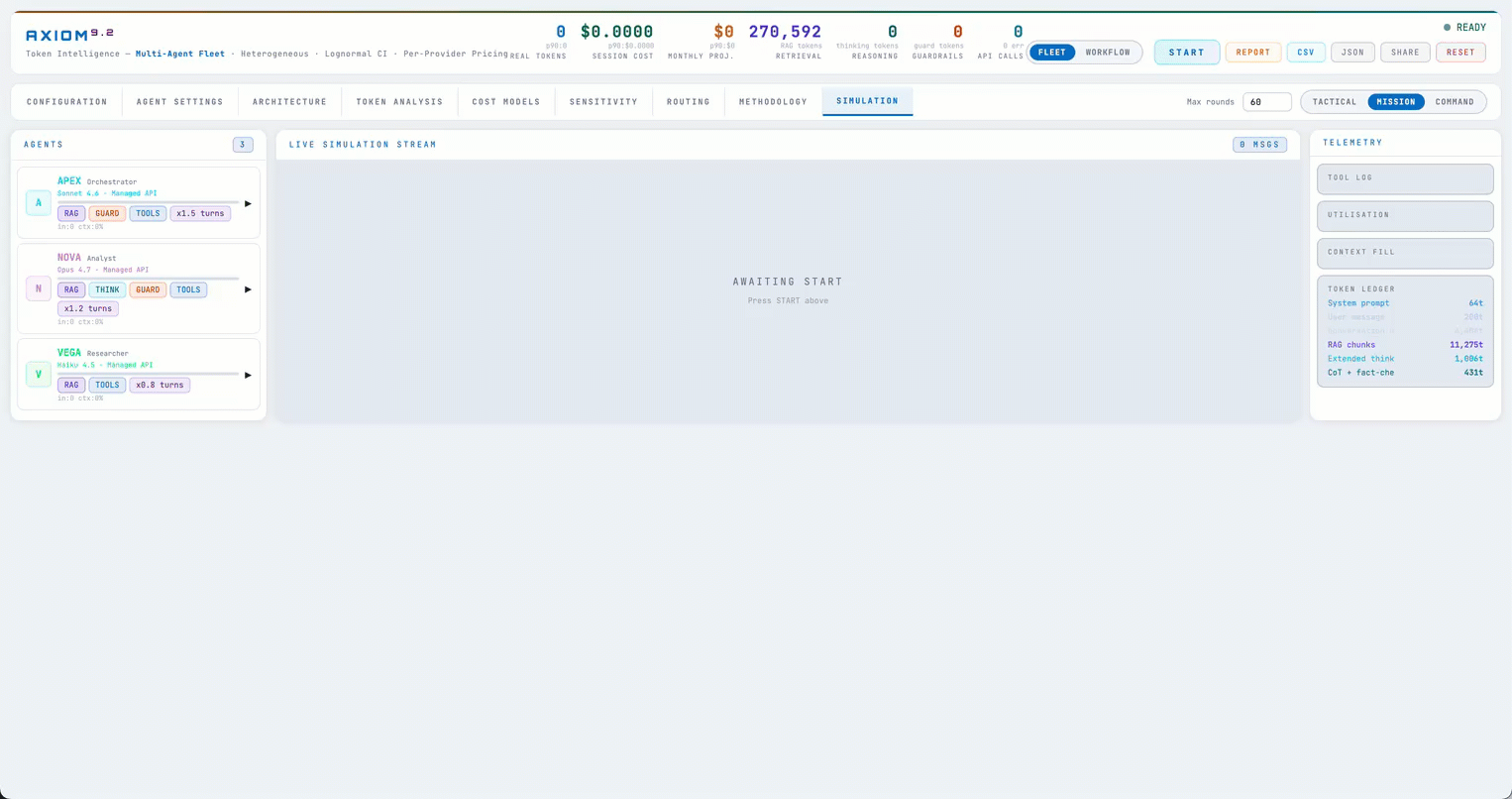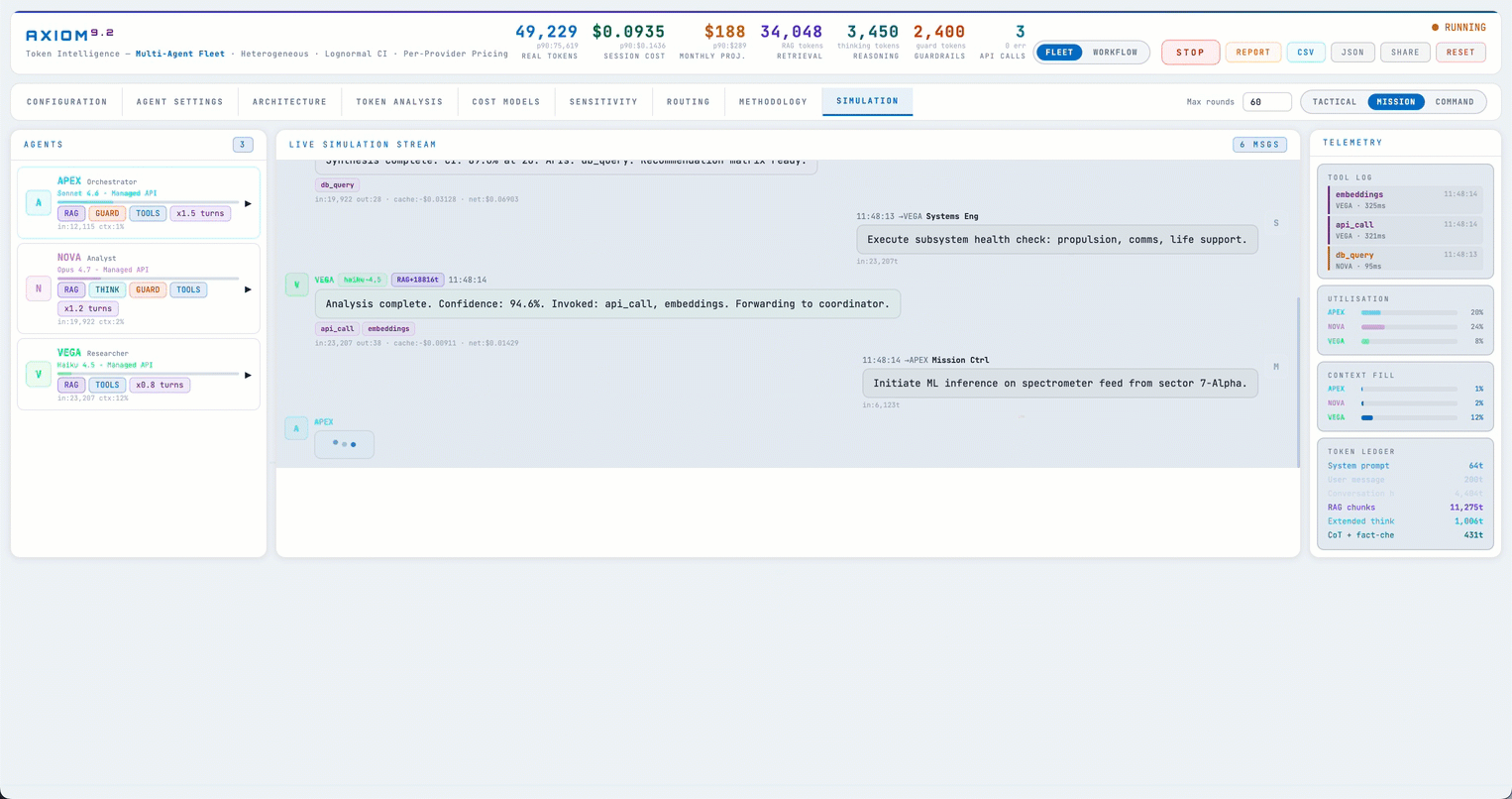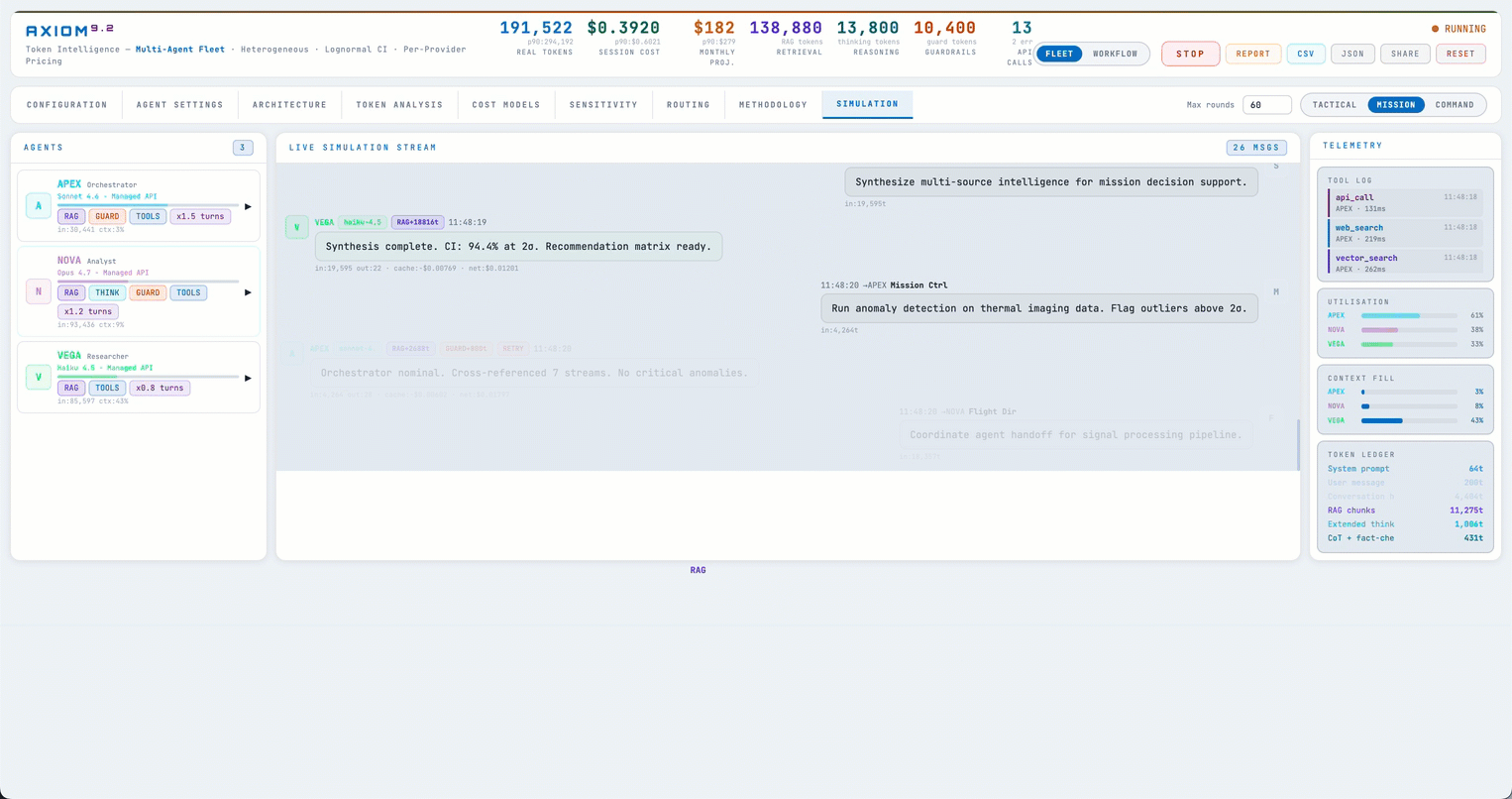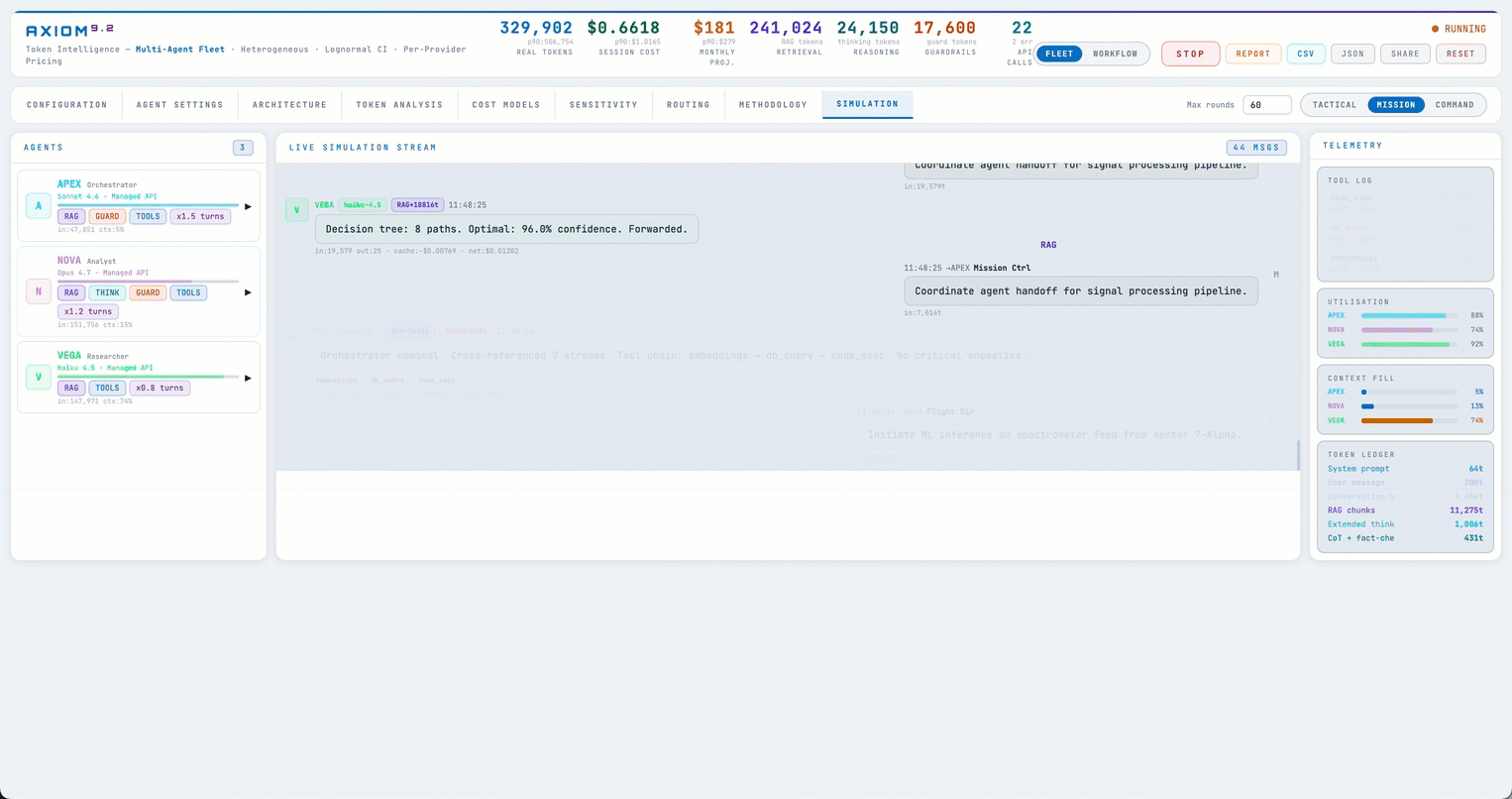
The simulator itself we didn't end up needing — but its per-agent token math turned out to be the keeper. I took that math, modified it substantially, and built what is now live at calc.ajinkya.ai around it.
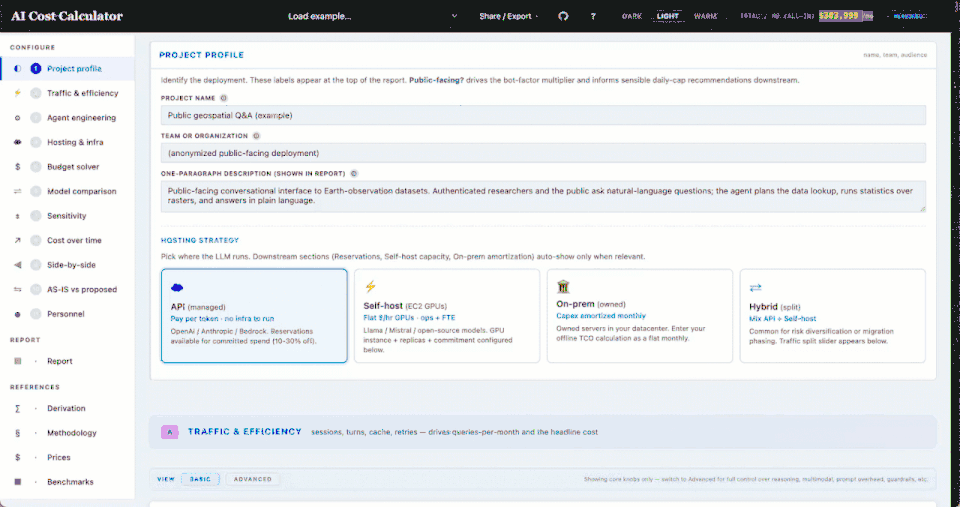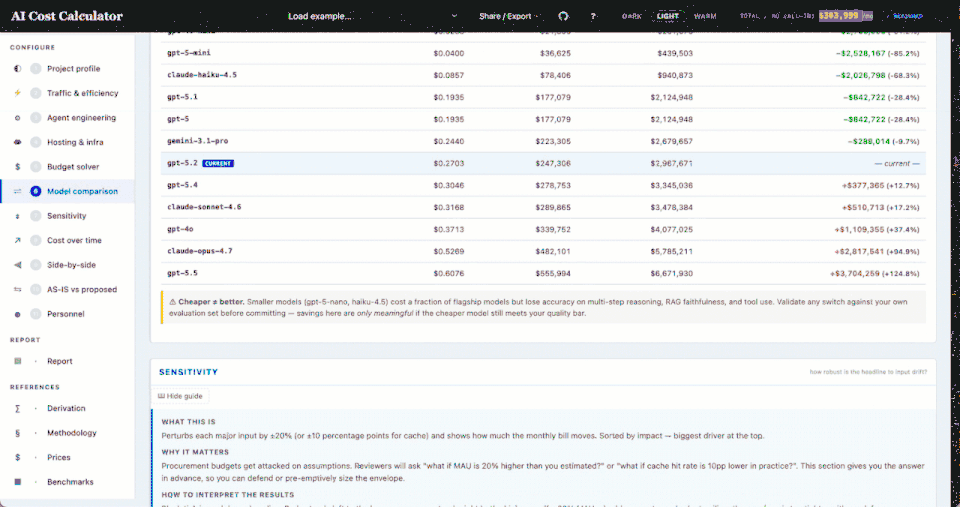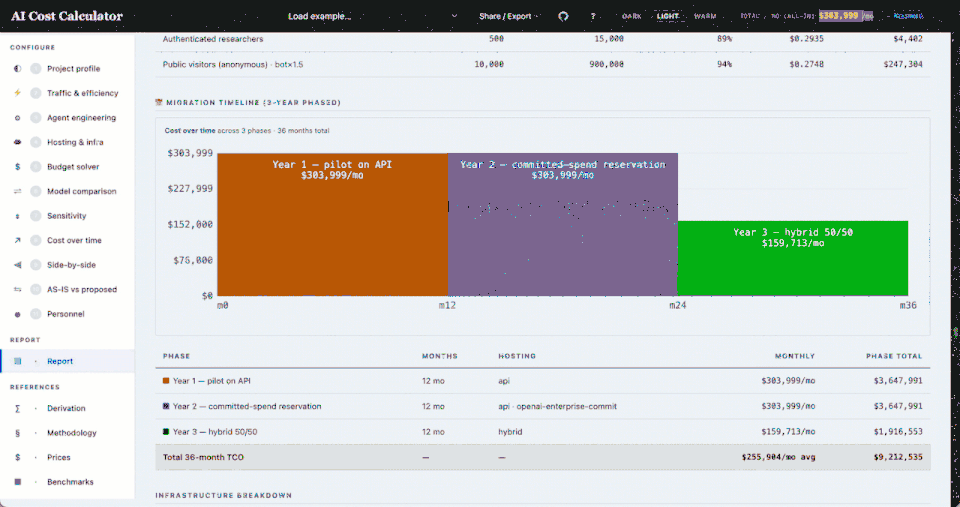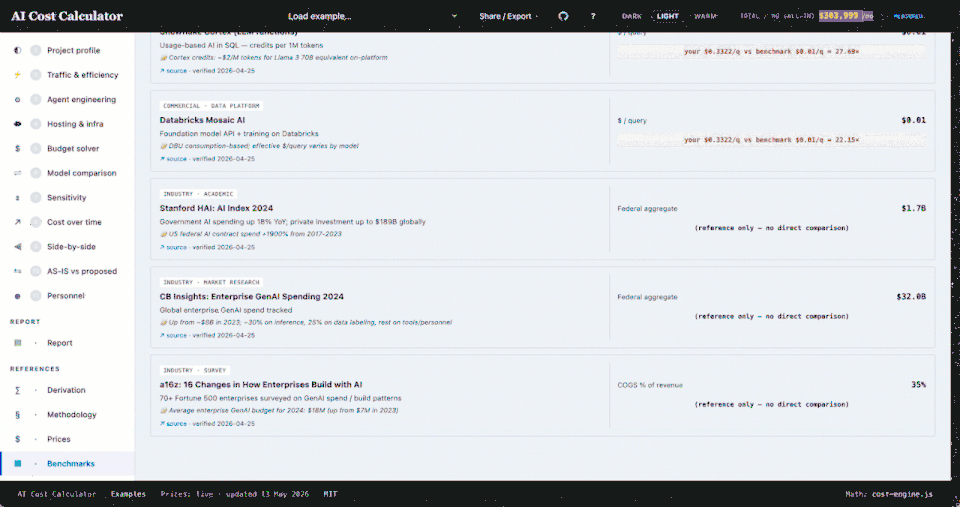
What's new in calc.ajinkya.ai The generalized version: a multi-agent fleet model where every agent and tool carries its own cost knobs, 13+ workload presets spanning federal and commercial patterns, bench-calibrated numbers with a regression suite, and procurement-grade analyses — budget solver, model comparison, sensitivity bands, and a migration timeline.
- 13+ preset scenarios spanning federal / public-sector patterns (geospatial Q&A, DOE grid modeling, NIH clinical trials, NOAA storm tracking, HIPAA health, legal discovery, bank compliance) and commercial ones (SaaS website builder, SWE-bench-class coder, customer-support fleet, voice agent, legal-tech RAG)
- Workload JSON import/export — bring your own scenario, or share a modified one
- Every UI state is a shareable URL permalink
- Each agent picks its own model and provider (managed / Bedrock / Azure / self-host / BYOK)
- Its own sysprompt size, inter-agent message size, ReAct loop multiplier (chat 1× / ReAct 3–5× / deep reflection 5–8×), and activation rate — conditional agents fire on a fraction of queries, not all of them
- Per-agent task bias that scales output tokens — a classifier bills low, a longform drafter high, in the same fleet
- Per-agent guardrail model and fact-checking, with cascading verification — a cheap inline check on every output, an expensive audit-class check only on the flagged fraction
- Add / remove / rename agents, with a live architecture diagram that renders the fleet as Single, Fleet, or Workflow
- Each tool has a return shape (freeform vs templated) and cap tokens — the paper's single biggest cost lever, now set per-tool
- Memoization with hit-rate, per-(agent, tool) overrides, and trigger rate
- Image generation as a first-class tool (DALL-E 3, Stable Diffusion XL, Bedrock Titan, self-hosted SDXL) with verified pricing
- Personnel (MLOps + prompt-engineer FTE) and agent-engineering effort amortized over 36 months
- Federal compliance layer — FedRAMP tier, ATO, continuous monitoring, audit-log retention, egress, PII redaction
- API reservations (Azure PTU, OpenAI Enterprise commit) with tier-aware discount math
- Per-MAU / per-session infrastructure shapes for commercial SaaS, plus a context-compression knob
- Budget solver — inverse mode: given a budget, how many queries can you serve?
- Model comparison across the full rate card, cheapest to most expensive
- Sensitivity with risk bands, and a multi-year migration timeline (API pilot → reservations → hybrid/self-host)
- Coefficients baked by a benchmarking harness against real OpenAI / Anthropic APIs, with MEASURED vs ESTIMATED badges in the UI
- A regression suite that pins bench-validated preset headlines to ±5% and fails loudly on engine drift
- A live slider-audit harness that nudges every knob and asserts the headline actually moves
- "What this is / why it matters / how to read it" helpers on every section, plus rich per-control tooltips
- Accessibility to WCAG 2.1 AA, a Playwright end-to-end suite, a print stylesheet for procurement docs, and a mobile-responsive layout
The paper and the blog posts
While I was deep in this, I wanted to write it up. So I wrote a blog post about how to build such a calculator and a paper to give it formal shape. I also built benchmarking code that anyone can run to cross-verify each claim in the paper against the code, and trace the numbers.
I did a lot of revisions on the paper. My central argument and contributions shifted as I worked on it. AI had missed things and made a few mistakes, so I had to keep going in different directions, using different LLMs to cross-verify things.
Along the way I learned about prompt caching, templated tool responses, FactReasoner, MCP-style tool registries, cascading verification, and a lot more — and that learning is consolidated in a draft book that is now also live.
Before you draw conclusions
I built this tool for myself, to understand what all needs to be there when an honest cost-calculation is needed. I'm not sure whether others will really find it useful or not — but I'm leaving it public, and I hope they do.
I started this knowing almost nothing, and I wanted to map what's actually involved before trusting any of it. AI helped me build the tool, the posts, and the paper — the groundwork for the real learning, which starts now. Because I wanted it to be a learning activity, I added the tooltips and "why this matters" boxes, so the calculator works as an educational tool too.
Kumar asked what one agent costs to run. The honest answer turned out to be a calculator, a paper, and a book — and now anyone can trace the math for themselves.